Apparently OCR software sometimes still has trouble interpreting older books:
[A]s Sarah Wendell, editor of the Romance blog Smart Bitches, Trashy Books noticed recently, something has gone awry. Because, in many old texts the scanner is reading the word ‘arms’ as ‘anus’ and replacing it as such in the digital edition. As you can imagine, you don’t want to be getting those two things mixed up.
The resulting sentences are hilarious, turning tender scenes of passionate embrace into something much darker, and in some cases, nearly physically impossible. The Guardian’s Alison Flood quotes some of the best:
From the title Matisse on the Loose: “When she spotted me, she flung her anus high in the air and kept them up until she reached me. ‘Matisse. Oh boy!’ she said. She grabbed my anus and positioned my body in the direction of the east gallery and we started walking.”
And ‘”Bertie, dear Bertie, will you not say good night to me” pleaded the sweet, voice of Minnie Hamilton, as she wound her anus affectionately around her brother’s neck. “No,” he replied angrily, pushing her away from him.”‘ Well, wouldn’t you?
As Flood notes, a quick search in Google Books reveals that the problem is widespread. Parents should keep their children away from the ebook edition of the 1882 children’s book Sunday Reading From the Young. It all seems perfectly innocent until… “Little Milly wound her anus lovingly around Mrs Green’s neck and begged her to make her home with them. At first Mrs Green hesitated.” And who can really blame her?
Clbuttic.
The Inner Drive Extensible Architecture™ is about to get wider distribution.
After 11 years of development, I think it's finally ready for wider distribution. And, who knows, maybe I'll make a couple of bucks.
I've updated the pricing structure and the license agreement, and in the next week or so (after some additional testing), I'm going to release it to NuGet.
That doesn't make it free; that makes it available. (Actually, I am making it free for development and testing, but I'm charging for commercial production use.)
I'll have more to say on this once it's released.
I don't know how this little snippet of code got into a project at work (despite the temptation to look at the file's history):
Search = Search.Replace("Search…", "");
// Perform a search that depends on the Search member being an empty string
// Display the list of things you find
First, I can't fathom why the original developer made the search method dependent on a hard-coded string.
Second, as soon as the first user hit this code after switching her user profile to display Japanese, the search failed.
The fix was crushingly simple:
var localizedSearchPrompt = GetLocalizedString("SearchPrompt");
Search = Search.Replace(localizedSearchPrompt, string.Empty);
(The GetLocalizedString method in this sample is actually a stub for the code that gets the string in the current user's language.)
The moral of the story is: avoid hard-coded strings, just like you've been taught since you started programming.
I had planned to post some photos tonight showing the evolution of digital cameras, using a local landmark, but there's a snag. The CF card reader I brought along isn't showing up on my computer, even though the computer acknowledges that something is attached through a USB port.
As I'm visiting one of the most sophisticated and technological cities in the world, I have no doubt I can fix this tomorrow. Still, it's always irritating when technology that worked a few days ago simply stops working.
For those doubting my troubleshooting skills, I have confirmed that the CF card has all the photos I shot today; that the computer can see the CF card reader; and that the computer can connect effectively to other USB attachments. The problem is therefore either in the OS or in the card reader, and I'm inclined to suspect the card reader.
The repercussions from Monday's data-recovery debacle continued through yesterday.
By the time business started Tuesday morning, I had restored the client's application and database to the state it had at the moment of the upgrade, and I'd entered most of their appointments, including all of them through tomorrow (Thursday). When the client started their day, everything seemed to be all right, except for one thing I also didn't know about their business: some of their customers pay them based on the appointment ID, which is nothing more than a SQL IDENTITY column in the database.
If you know how databases work, you know that IDENTITY columns are officially non-deterministic. In this specific case, the column increments by one every time it adds a row, but also in this specific case, I didn't re-enter the data in the same order it was originally entered, since I prioritized the earlier appointments.
We've gotten through the problem now, and the client no longer want to put my head on a spike, so I will now take a moment for an after-action review that might help other software developers in the future.
First, the things I did right:
- When I deployed the upgrade Saturday, I preserved the state of the database and application at exactly that moment.
- All of the data in the system, every field of it, was audited. It was trivially easy to produce a report of every change made to the system from roll-out Saturday afternoon through roll-back Monday night.
- When I rolled back the upgrade Monday night, I preserved the state of the upgraded database and application at exactly that moment.
- When the client first noticed the problem, I dropped everything else and worked out a plan with them. The plan centered around getting their business back up first, and then dealing with the technology.
- Their customers were completely back to normal at the start of business Tuesday.
- The application runs on Windows Azure, which made preserving the old application state not only easy, but possible.
So what should I have done better?
- My biggest error was overconfidence in my ability to roll back the upgrade. No matter what other errors I made, this was the root of all of them.
- The second major error was not testing the UI on Internet Explorer 8. Mitigating this was the fact that neither I nor my client was aware that the bulk of their customers used IE8. However, given that people using IE8 were totally unable to use the application, even if the numbers of customers using IE8 was very small, the large impact should have put IE8 near the top of my regression test checklist.
- Instead of spending a couple of hours re-entering data, I should have written a script to do it.
- I have always regretted (though never more than today) publicizing the appointments IDENTITY column to the end user, because it's normal they'd use this ID for business purposes. This illustrates the danger—not just the sloppy design—of using a single database field for two purposes. Any future version of the application will have an OrderID field that is not a database plumbing field.
All in all, the good things outweighed the bad, and I may get back in my client's good graces when I roll out the next update. You know, the one that works on IE8, but still solves the looming problem of the platform's age.
I've just picked up Bob Martin's The Clean Coder: A Code of Conduct for Professional Programmers .
.
I'm just a couple chapters in, and I find myself agreeing with him vehemently. So far, he's reinforcing the professional aspects of the profession. Next chapters will TDD, testing, estimation, and a bunch of other parts of the profession that are more difficult than the actual coding part.
More later.
I just did a dumb thing in Mercurial, but Mercurial saved me. Allow me to show, vividly, how using a DVCS can prevent disaster when you do something entirely too human.
In the process of upgrading to a new database package in an old project, I realized that we still need to support the old database version. What I should have done involved me coming to this realization before making a bucket-load of changes. But never mind that for now.
I figured I just need to create a branch for the old code. Before taking this action, my repository looked a like this:
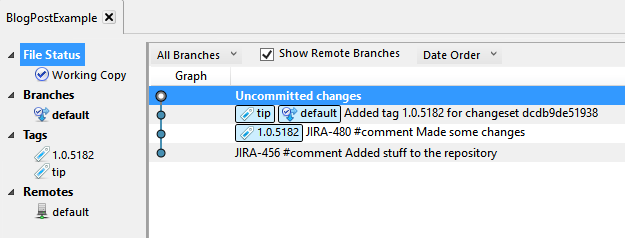
Thinking I was doing the right thing, I right-clicked the last commit and added a branch:
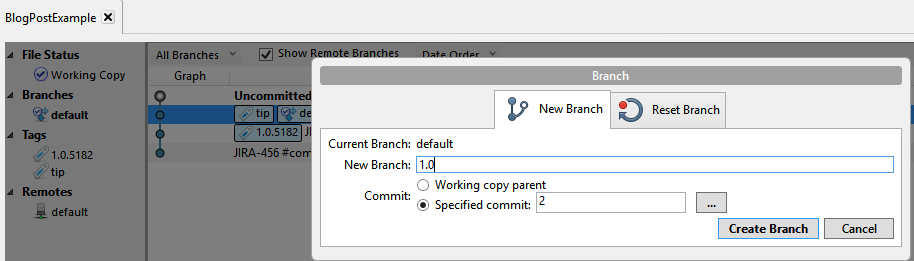
Oops:
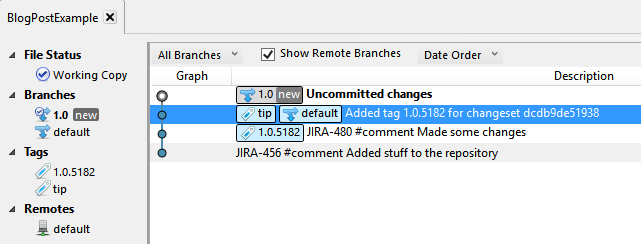
Well, now I have a problem. I wanted the uncommitted changes on the default branch, and the old code on the 1.0 branch. Now I have the opposite condition.
Fortunately this is Mercurial, so nothing has left my own computer yet. So here's what I did to fix it:
- Committed the changes to the 1.0 branch of this repository. The commit is in the wrong branch, but it's atomic and stable.
- Created a patch from the commit.
- Cloned the remote (which, remember, doesn't have the changes) back to my local computer.
- Created the branch on the new clone.
- Committed the new branch.
- Switched branches on the new clone back to default.
- Applied the patch containing the 2.0 changes.
- Deleted the old, broken repository.
Now it looks like this:
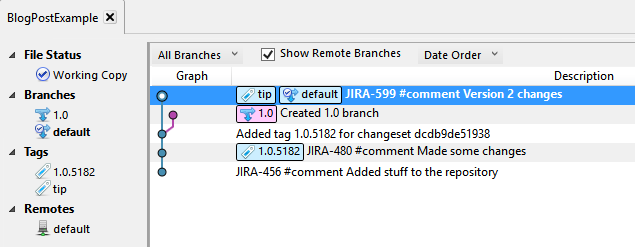
Now all is good in the world, and no one in my company needs to know that I screwed up, because the screw-up only affected my local copy of the team's repository.
It's a legitimate question why I didn't create a 2.0 branch instead. In this case, the likelihood of an application depending on the 1.0 version is small enough that the 1.0 branch is simply insurance against not being able to support old code. By creating a branch for the old code, we can continue advancing the default branch, and basically forget the 1.0 branch is there unless calamity (or a zombie application) strikes.
The test configuration earlier today wasn't the problem. It turned out that MSBuild simply didn't know it had to pull in the System.Web.Providers assembly. Fortunately, this guy suggested a way to do it. I created a new file called AssemblyInit that looks like this:
using System.Diagnostics;
using System.Web.Providers;
using Microsoft.VisualStudio.TestTools.UnitTesting;
namespace MyApp
{
public class AssemblyInit
{
[AssemblyInitialize]
public void Initialize()
{
Trace.WriteLine("Initializing System.Web.Providers");
var dummy = new DefaultMembershipProvider();
Trace.WriteLine(string.Format("Instantiated {0}", dummy));
}
}
}
That does nothing more than create a hard reference to System.Web.Providers, causing MSBuild to affirmatively import it.
Now all my CI build works, the unit tests work, and I can go have a weekend.
One of my tasks at my day job today is to get continuous integration running on a Jenkins server. It didn't take too long to wrestle MSBuild to the ground and get the build working properly, but when I added an MSTest task, a bunch of unit tests failed with this error:
System.IO.FileNotFoundException: Could not load file or assembly 'System.Web.Providers, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35' or one of its dependencies. The system cannot find the file specified.
The System.Web.Providers assembly is properly referenced in the unit test project (it's part of a NuGet package), and the assembly's Copy Local property is set to True.
When the unit tests run from inside Visual Studio 2013, they all work. When ReSharper runs them, they all work. But when I execute the command line:
MSTest.exe /resultsfile:MSTestResults.trx /testcontainer:My.Stupid.Test\bin\My.Stupid.Test.dll /test:MyFailingTest
...it fails with the error I noted above.
I'll spare you the detective work, because I have to get back to work, but I did find the solution. I marked the failing test with a DeploymentItemAttribute:
[TestMethod]
[DeploymentItem("System.Web.Providers.dll")]
public void MyFailingTest()
{
try
{
DoSomeTestyThings();
}
finally
{
CleanUp();
}
}
Now, suddenly, everything works.
And people wonder why I hate command line crap.